AI Core
Fundamentals of AI models, architecture, and how they work
221 episodes · Page 5 of 10

#2204: Memory Without RAG: The Real Architecture
mem0, Letta, Zep, and LangMem solve agent memory differently than RAG. Here's what's actually happening under the hood.

#2196: The Invisible Workforce Behind AI
Annotation is the invisible foundation of AI—and a $17B industry by 2030. Here's what dataset curators actually need to know about the tools, platf...

#2195: Nash's Real Genius (And Why the Movie Got It Wrong)
The bar scene in A Beautiful Mind is mathematically wrong—and it obscures Nash's actual breakthrough. We trace the real ideas from his 1950 papers ...
#2188: Is Emergence Real or Just Bad Metrics?
The debate over whether AI models exhibit genuine emergent abilities or just appear to because of how we measure them—and why it matters for safety...

#2187: Why Claude Writes Like a Person (and Gemini Doesn't)
Claude produces prose that sounds human. Gemini reads like Wikipedia. The difference isn't capability—it's how they were trained to think about wri...

#2181: When RAG Becomes an Agent
RAG in chatbots is simple retrieval. RAG in agents is a multi-step decision loop. Here's what actually changes.
#2177: Skip Fine-Tuning: Shape LLMs With Alignment Alone
Can you build a personalized LLM by skipping traditional fine-tuning and using only post-training alignment methods like DPO and GRPO? We break dow...

#2172: Council of Models: How Karpathy Built AI Peer Review
Andrej Karpathy's llm-council uses anonymized peer review to make language models evaluate each other fairly—but can it really suppress model bias?

#2164: Why Bigger Context Windows Don't Fix Attention
Frontier models have million-token context windows, but attention degrades well before you hit the limit. New research reveals why bigger isn't bet...

#2160: Claude's Latency Profile and SLA Guarantees
Claude is measurably slower than competitors—and Anthropic's SLA promises are even thinner than the latency numbers suggest. What enterprises actua...
#2146: The AI Wargame's Flat Hierarchy Problem
AI wargames treat NGOs and nuclear powers as equals. That's a dangerous flaw for real-world policy planning.

#2144: AI Wargaming: One Model or Many?
Should geopolitical AI simulations use one model or many? We debate the pros and cons of a single-model approach.
#2139: AI Wargame Memory: Beyond the Context Window
Why simply extending context windows fails in multi-agent simulations, and how layered memory architectures preserve strategic fidelity.

#2136: The Brutal Problem of AI Wargame Evaluation
Most AI wargame simulations skip evaluation entirely or rely on token expert reviews. This is the field's biggest credibility problem.

#2135: Is Your AI Wargame Signal or Noise?
Monte Carlo methods promise statistical rigor for AI wargaming, but the line between genuine insight and sampling noise is thinner than you think.

#2133: Engineering Geopolitical Personas: Beyond Caricatures
How to build LLMs that simulate state actors with strategic fidelity, not just surface mimicry.

#2129: Shifting Left on Hallucinations
Stop hoping your AI doesn't lie. We explore the shift to deterministic guardrails, specialized judge models, and the tools making agents reliable.

#2125: Why Agentic Chunking Beats One-Shot Generation
A single prompt can't write a 30-minute script. Here’s the agentic chunking method that fixes coherence.

#2123: Human Reaction Time vs. AI Latency
We obsess over shaving milliseconds off AI response times, but human biology has a hard limit. Here’s why your brain can’t keep up.
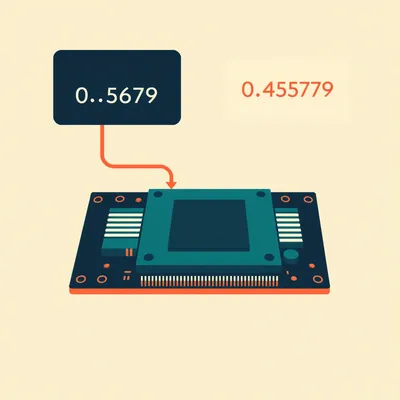
#2115: Why AI Answers Differ Even When You Ask Twice
You ask an AI the same question twice and get two different answers. It’s not a bug—it’s physics.

#2113: Goldfish vs Elephant: The Stateful Agent Dilemma
Stateless agents are cheap and fast, but stateful ones remember your window seat. Which architecture wins?

#2110: Tuning AI Personality: Beyond Sycophancy
AI models swing between obsequious flattery and cold dismissal. Here’s why that happens and how to fix it.

#2109: AI Is Forcing You to Use React
AI tools are reshaping developer stacks, favoring React and Postgres over niche frameworks.

#2092: Why AI Thinks You're American (Even When You're Not)
Even when we tell Gemini we're in Jerusalem, it defaults to US-centric assumptions. We explore the root causes of this persistent AI bias.